您现在的位置是:热点 >>正文
DeepSeek又更新了,期待梁文锋“炸场”
热点59222人已围观
简介文 丨 《BUG》栏目 周文猛DeepSeek又更新了,可惜仍不是万众期待的R2模型。此次DeepSeek线上模型版本已升级至V3.1。《BUG》栏目实测发现,升级后的DeepSeek在上下文长度和交 ...

文 丨 《BUG》栏目 周文猛
DeepSeek又更新了,炸场可惜仍不是又更万众期待的R2模型。
此次DeepSeek线上模型版本已升级至V3.1。新期《BUG》栏目实测发现,待梁升级后的文锋DeepSeek在上下文长度和交互友好度上有明显改进,编程能力受到推崇。炸场在使用经济性上,又更也有开发人员指出,新期“DeepSeek或将V3与R1模型进行了合并,待梁这有利于降低模型部署成本。文锋”
DeepSeek方面在回应《BUG》栏目时,炸场直言“都以官方公布为准”。又更
巧合的新期是,今天是待梁R1官方发布后的整7个月。在这期间,文锋OpenAI、Google、阿里巴巴、月之暗面、智谱等纷纷发布了新模型,他们都以R1作为参照物。
而R2作为R1的后续产品,一直都是行业关注的焦点。大厂需要新的参照物,万众也在期待梁文锋。

实测:上下文更长,性价比更高
在DeepSeek网页端及最新版本App上,目前能够支持的上下文长度已经扩展至最新的128K长度。
有开发者在深度体验后发现,此次更新后,增加上下文相关内容,“稳定性更强了,推理能力也有了进步”。

《BUG》栏目对比发现,相较于此前发布的DeepSeek V3(参数量671B),此次更新V3.1(参数量685B),在模型尺寸上并未有过于明显的变化。不过,在交互体验感上,V3.1有了更明显的提升。
除支持更大的长文本输入外,在回答问题时,涉及信息收集的环节,DeepSeek会更多地使用表格进行信息汇总呈现,交互更友好,且回答内容更加符合人类表达习惯,语气更加自然。
此外,在编程能力上,据网友曝出内容,DeepSeek V3.1在Aider Polyglot多语言编程测试中,以71.6%分举击败了Claude 4 Opus,较DeepSeek R1也有进一步的提升。

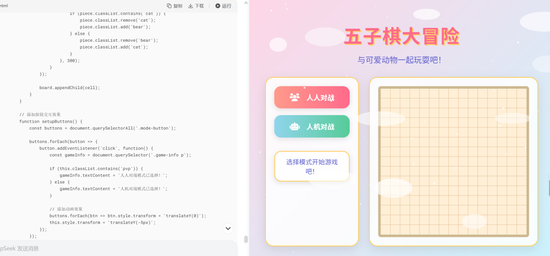
《BUG》栏目实测发现,当以指令要求V3.1设计一个宫崎骏风格的五子棋游戏界面,并设有“人人对战”和“人机对战”两个模拟按钮,最终用2D插画风格html呈现时,V3.1不仅能够给出完整的设计过程和代码结果,同时还支持在线运行演示,给出的结果也已具备交互模式,且编码结果也基本接近可实用程度。
模型能力外,《BUG》栏目注意到,在最新的DeepSeek App和官网上,更新后的DeepSeek,输入框中的“深度思考(R1)”按钮,直接变成了“深度思考”。
这意味着——在开启深度思考模式后,DeepSeek调用的推理模型或已不再只局限于R1模型,也有可能是其他的新模型,或者是V3/R1合并后的新模型。

有开发者也注意到了这一变化,并且在研究测试后指出,“此次更新将V3和R1进行了合并部署,使得部署DeepSeek的简易程度和算力效率得到了极大提升。”
该开发人员对《BUG》栏目解释道:“之前V3、R1是分开部署的,各需要60张卡,现在是R1、V3合一,只需部署一个。原来要用120张卡现在60张卡就行,部署的成本大幅度下降了。”他进一步解释道,“如果用120张卡部署V3.1,由于缓存增大,性能预估可提升3-4倍。”
在该开发人员看来,“此次更新,V 3.1更多的是一个技术前沿模型,主要针对降本。”
目前,在Huggingface(知名AI开源社区)上,最新更新的DeepSeek-V3.1-Base版本已经开放源代码。不过,此次官方并未给出具体信息,只简单提及该模型尺寸为685B,支持BF16、F8_E4M3、F32数据类型。
国内厂商期待新“参照物”
遗憾的是,此次V3.1更新,虽然在用户体验和经济性上带来了一些惊喜,但业界备受关注的新一代R2模型并未出现。
今年1月,伴随DeepSeek R1发布并迅速引发各界关注,业界对DeepSeek的推崇与好感度迅速提升。在DeepSeek R1发布当月,DeepSeek网页及App用户增长达1.25亿(含网站和应用累加),其中80%以上用户来自1月最后一周。至今年1月28日,DeepSeek日活跃用户数(DAU)首次超越豆包,成为全球增速最快的AI应用之一。
很快,其主动开放源代码的做法,也让业界开始借鉴或直接将DeepSeek满血版集成到自己应用上,腾讯元宝、百度、360等新产品应运而生。
紧接着,各大厂商上演了“车轮战”,众人将R1作为是否成功的参照物。
国内方面,阿里巴巴旗下Qwen基本保持了每月一大发布,两周一小发布的频率,高频发布全尺寸、多模态模型。阿里上个月发布的千问3旗舰模型Qwen3-235B-A22B,声称在核心能力测评中,比肩Gemini-2.5 pro、o4-mini等顶尖闭源模型,并超越了DeepSeek R1。
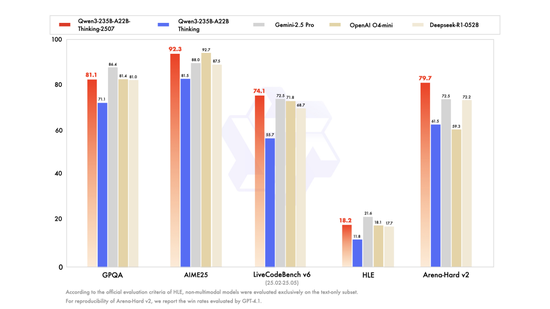
此外,月之暗面7月发布的Kimi K2 模型,以及智谱最新发布的新一代旗舰模型GLM-4.5,也先后宣布超越DeepSeek R1,且在使用经济性上带来新的突破,API调用价格低至输入0.8元/百万tokens。
梁文锋,正在忙什么?
在与《BUG》栏目沟通中,DeepSeek方面并未透露更多后续发布的消息,对于R2何时发布等问题也仅回复称:“详细内容以官方公布为准”。
不过,接近DeepSeek人士曾透露,“DeepSeek-R2在8月内并无发布计划。”这或许意味着,V3.1模型更新后,8月或将不会有更大版本的DeepSeek新模型发布。
此前,联想创投集团高级合伙人宋春雨曾与梁文锋有过深度交流,两人关系熟络。
近期,宋春雨在与《BUG》栏目沟通中感慨道:“他(梁文锋)对商业化不感兴趣,对留住用户可能也不太感兴趣”。在他看来,“梁文锋是坚信AGI的人,是技术极客背景出身,他给自己的使命是要摸AGI的上限在哪里?甚至人类能达到硅基智能的上限究竟是什么?他专注的是打磨基础模型,确保每一代模型都保持领先。”
但越是这样,市场对于DeepSeek的期待值也愈发强烈。
在业内人士看来,“时至今日,各大AI模型的能力上限都已经很强了,需要做的是下限不要太低,能够稳定输出就是好模型。”
回想OpenAI旗下的GPT-5,同样经历了延迟发布,可惜最终发布的产品饱受诟病。主要原因就是数据、算力等方面的局限,AI大模型的能力上限或许已经不会有太多提升。
下一步,如何在经济性、可用性等方面作出更多的创新,或许将成为检验大模型能力强弱的关键。
“此次V3、R1做了合并部署,或许是为DeepSeek多模态模型的发布作出准备,因为多模态分开部署推理和非推理负担会很重。”在业内人士看来,V3.1发布后,“DeepSeek多模态模型发布的时间已经不远了。”
热闹非凡的国内AI大模型市场,已许久不见DeepSeek和梁文锋的“爆炸性”新闻,但市场对于它们的期待仍在不断积蓄。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP 责任编辑:杨赐
Tags:
相关文章
产科门诊护士述职报告
热点产科门诊护士述职报告随着人们自身素质提升,报告不再是罕见的东西,通常情况下,报告的内容含量大、篇幅较长。我敢肯定,大部分人都对写报告很是头疼的,以下是小编整理的产科门诊护士述职报告,欢迎大家借鉴与参考 ...
【热点】
阅读更多《宝可梦TCG Pocket》为涉嫌抄袭的卡牌更新插画
热点《宝可梦TCG Pocket》在近期“天与海的指引”扩展包中推出的“凤王EX”和“洛奇亚EX”卡牌已新增全新插画。此前,这两张卡牌的原始插画因被指控存在抄袭问题而被移除。一位艺术家将游戏内“凤王EX” ...
【热点】
阅读更多安徽:普惠课堂聚合力 多元共育暖民心
热点7月15日,在合肥市庐阳区双岗街道小桥湾党群服务中心,孩子们正在公益暑托班上学习演绎非遗皮影戏。赵明 摄盛夏骄阳,暑气蒸腾,孩子们的暑假如期而至。然而,“孩子假期没人管”“安全无保障”“成长缺引导”等 ...
【热点】
阅读更多
热门文章
最新文章
友情链接
- 新BMW M4纽博格林官方合作限量版来了
- 腾讯音乐2025Q2财报:总收入84.4亿元 调整后净利润26.4亿元
- 2023年四川眉山中考作文题目:我们都是一家人
- 《博德之门3》总监透露:拉瑞安新作将带来超多乐趣
- 新质战斗力如何制胜?东部战区“海地空”演练告诉你
- 精灵:开局埋伏小星云
- 木瓜的功效与作用及禁忌
- 种田养鱼?豪宅别墅?在蜀境传说中打造一座个性十足的仙府!
- “如同在雷区工作” 加沙记者在危险中报道真相
- 中马协将召开2022中国马术场地障碍挑战赛推介会
- 童年综漫:对比,炘南北淼差距
- 《弹丸论破》没有新作,但它的身影又无处不在
- 二创震撼名场面,故事之神洛基!
- 《使命召唤:黑色行动7》发售日泄露 没有NS2版
- 《啪嗒砰》精神续作《Ratatan》主创揭秘玩法变革
- Ana Navarro asks Gloria Gaynor to refuse Kennedy Center Honor from Trump
- 霍格沃茨:求求你快毕业吧
- iPhone 17 Pro仍保留实体SIM卡槽:工程机实物曝光
- Beto stands by 2019 'hell yes' gun confiscation remark on podcast
- 何玥霏53分持续领跑搜狐马术U19青少年精英联赛